



Published: .
The key takeaway for 2026: adapting user documentation and software user manuals for AI means transforming it from a passive reference manual into an active data layer for generative AI systems — this is the core of AI‑powered product documentation and establishing an AI layer for user documentation. The quality of responses from enterprise chatbots built on RAG (Retrieval-Augmented Generation) is determined not by the model itself, but by the knowledge corpus. Unstructured, contradictory, or outdated help systems are the primary cause of hallucinations—which in B2B scenarios translate directly into financial losses. Industry analysts estimate that budget overruns in AI projects are most often tied to poor source data quality. This article provides an overview for technical writers, AI engineers, and managers who want to prepare user guides for neural networks and turn them into a competitive advantage.
Contextual infrastructure: definition, semantic search, architecture
Contextual infrastructure refers to the set of methods, formats, and tools that ensure semantic coherence, unambiguity, and machine-readability of documentation at all levels—from raw text to vectorized representations and knowledge graphs, enabling semantic search in user manuals and beyond. Unlike traditional hierarchical help systems, it is built as a semantic graph, where each section is a node enriched with metadata (type, product version, target audience, prerequisites, errors), and the relationships between nodes are explicitly specified (see JSON‑LD and schemas such as Schema.org).
By 2026, reference documentation has officially become the fourth pillar of IT infrastructure—alongside code, data, and CI/CD. According to industry data, 68% of Fortune 500 companies now allocate a dedicated budget for "AI‑readiness of content," yet only 22% can claim to have mature practices in place. Many organizations acknowledge that their knowledge bases are unfit for machine processing—the gap between expectations and reality remains the primary barrier to effective AI adoption.
Why classic approaches fail with LLMs: a systematic analysis
Traditional software user manuals are designed for sequential reading by humans: topics like "How to do X" are siloed, examples are given without context, and terminology may vary. For an LLM—which has no inherent memory of what it has read beyond its context window—such material becomes a collection of loosely connected facts. The model cannot infer implicit relationships, leading to three classes of errors:
- Hallucinations — when the model "fills in" missing information.
- Contradictions — when the same operation is described differently in different places, and the model picks a random version.
- Context loss — when answering requires information from multiple sections, but the retriever cannot assemble it due to poor structure.
To address these issues, transforming support documentation with AI requires a shift from traditional hierarchical structures to a semantic graph. Let's compare the two approaches across key parameters:
| Parameter | Traditional Documentation | Contextual Infrastructure |
|---|---|---|
| Target consumer | Human (reading, visual search) | LLM / AI agent (retrieval, logical inference) |
| Structure | Hierarchical (sections → subsections) | Semantic graph + topics with metadata (version, type, dependencies) |
| Formats | HTML, PDF, Markdown (free text) | Markdown + frontmatter, OpenAPI/AsyncAPI, JSON‑LD, RDF, structured examples |
| Search & retrieval | Keyword‑based, full‑text search (BM25) | Hybrid search (BM25 + dense vectors), reranking, knowledge graph access |
| Content requirements | Uniqueness, SEO keywords | Unambiguity, consistency, explicit cross‑references (key for software user guides), machine‑readable markup |
| Quality metrics | Time to find, user satisfaction | Hit Rate@K, Mean Reciprocal Rank (MRR), chatbot answer accuracy, hallucination reduction |
| Update cycle | Quarterly / per release | CI/CD with commit‑based sync (docs‑as‑code) |
The critical difference: LLMs require explicit semantic connectedness. For example, if the action "approve order" is called one thing in one place and "confirm order" in another, the model may treat them as distinct operations. To address this, organizations implement URI-based glossaries and use variables (as in code) instead of hard‑coded names.
User documentation as a data layer: architecture and components for an AI assistants
The data layer for AI is a corpus optimized for the RAG pipeline — this is the foundation of how to build an AI assistant over documentation. A complete pipeline includes:
- Ingestion and cleaning — extracting content from all sources (repositories, wikis, support tickets). Tools: Unstructured, LlamaIndex (supports 100+ formats).
- Structuring and annotation — adding metadata (topic type, product, version, goal, complexity). Uses JSON‑LD schemas or Markdown frontmatter.
- Chunking — optimal chunk size for embeddings (512–1024 tokens) with overlap (10–15%) to preserve context at boundaries. Strategies: semantic (by sentences) or fixed‑size (by tokens).
- Vectorization — selecting embedding models (e.g., E5-Mistral, Cohere Embed v3, or OpenAI text-embedding-3-large) with domain adaptation (technical vocabulary often requires fine‑tuning on code and documentation corpora).
- Indexing and search — hybrid approach (BM25 + dense vectors) with subsequent reranking (cross‑encoder) to boost precision — a key technique for improving user documentation search with generative AI. Popular vector databases: Pinecone, Weaviate, Milvus.
- Monitoring and feedback — logging all queries, retrieved chunks, and user ratings for continuous improvement.
Real‑world case studies with metrics:
- MongoDB reworked 70% of its guides into semantically linked topics with explicit "related sections" and introduced a duplicate validator. Their internal AI assistant subsequently showed a 62% reduction in erroneous responses (measured by factual consistency on a test set of 500 questions).
- Google Cloud adopted standardized templates for each document type (concept, procedure, reference) and made "Prerequisites" and "Troubleshooting" sections mandatory. Gemini's answer accuracy on technical questions improved by 45% (measured using the BIG‑Bench QA subset).
- A 2025 study by a major European e‑commerce platform reported that switching to structured documentation cards for their internal LLM‑based support system reduced operator escalations by 37%.
Hidden complexities: systemic risks and mitigation
1. Invisibility of AI usage: a new type of analytics
Standard web analytics do not capture how an LLM "navigates" your documentation. RAG‑specific logging is essential: every chatbot query must record which chunks were used, their ranking, and the final answer. This helps identify "blind spots" (queries with no relevant chunks) and "noise" (frequently retrieved but irrelevant chunks). Tools: Arize, Honeycomb for tracing, as well as open‑source LlamaHub with customizable callbacks.

Military technical documentation in 2026: global standards and best practices

How to become an LLM expert in 2026: core skills for technical writers
How do you know if your user documentation is actually working?

Effective user documentation and FTUE in 2026: aligning help content with first impressions

Docs as Code for user documentation in 2026: when it works and when it doesn’t?

How to publish online user documentation: a practical guide for 2026

How to add annotations and captions to screenshots in MS Word in 2026?

Development of documentation for devices and industrial equipment: features, tools, special techniques

Development of documentation for production automation systems and business processes

Creating user manuals for accounting software

Developing user manual for ERP systems: features, tools, special techniques

Development of documentation for CAD and BIM systems: peculiarities, tools for its creation and real examples

How to choose a system for developing user documentation: SaaS or desktop software?

How to write a user manual for software or a WEB service: tips, tricks and tools

How to write user documentation for software: best programs and services

White Papers: Writing Cost-Effective Documentation for Software Systems

Why software documentation needs index and how to make it work efficiently

Agile Technical Writing Basics

Software Documentation in Scrum Projects

Windows Software Help Files Formats

Error Accessing and Displaying CHM Files: Reasons and Solutions

A Dozen Techniques to Improve Your Software Online Help
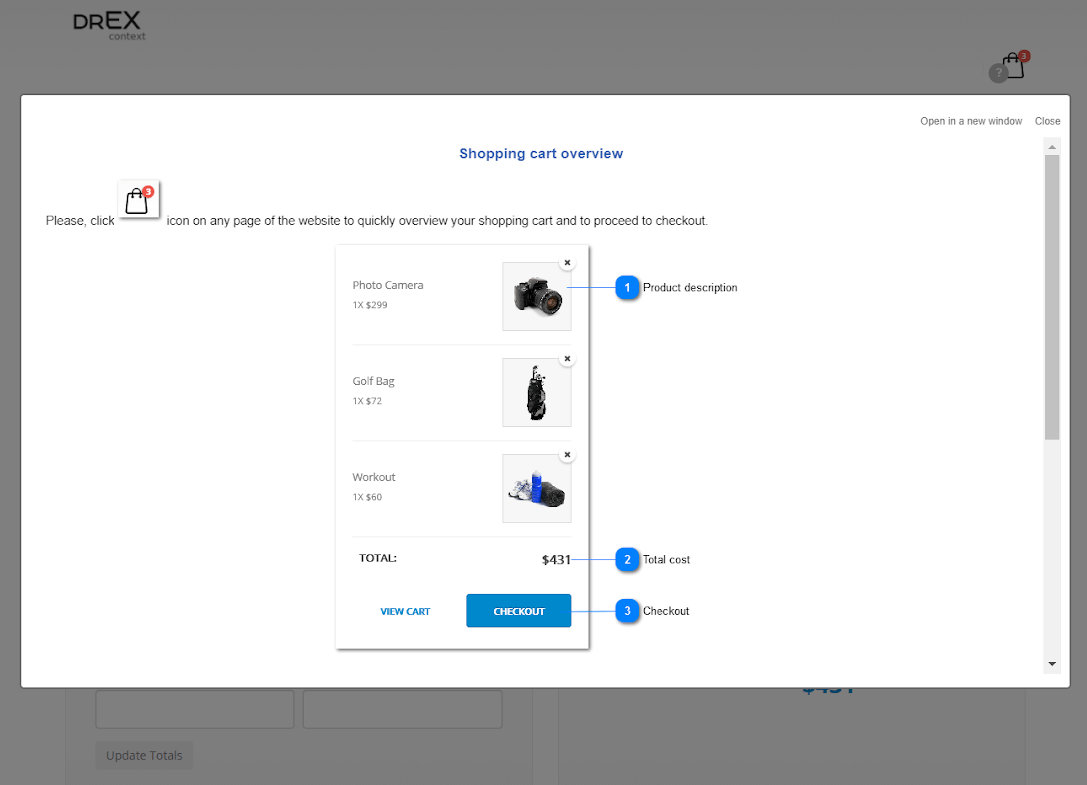
How to make a context help for a website or a web application with Dr.Explain
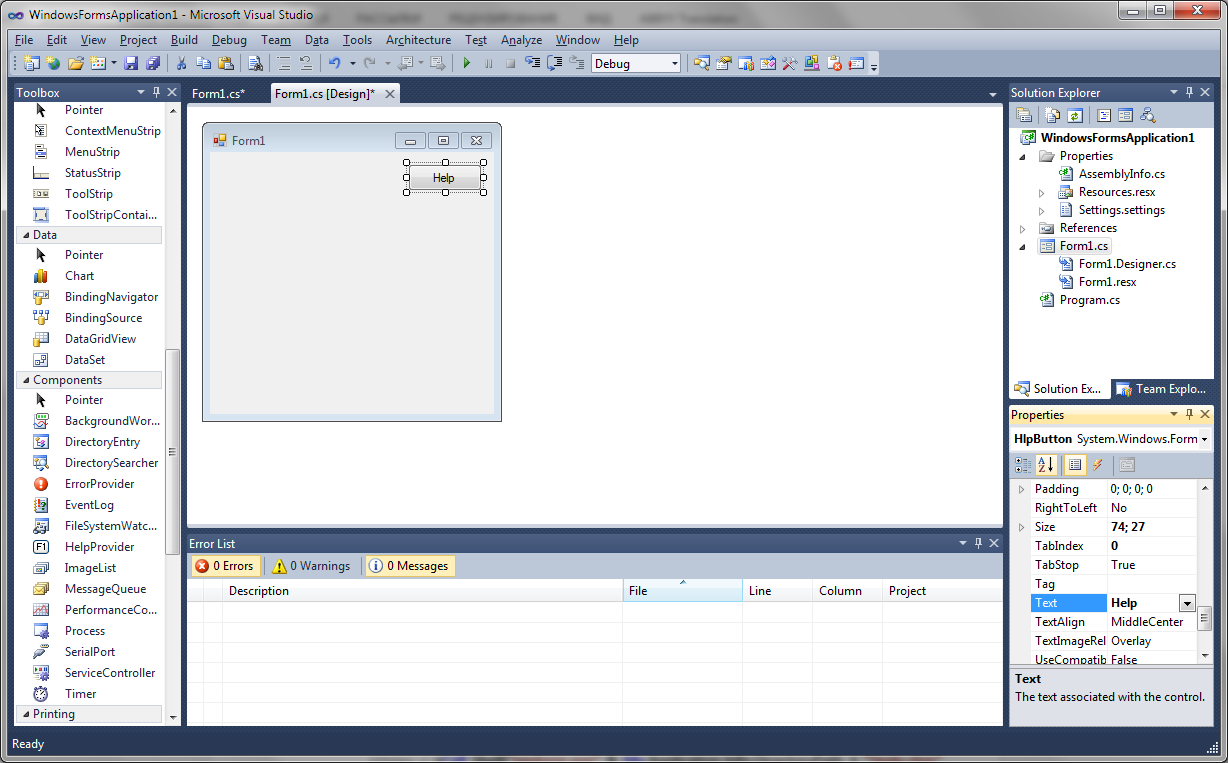
How to Create Help Files for .NET (C#) Windows-Application in Dr.Explain
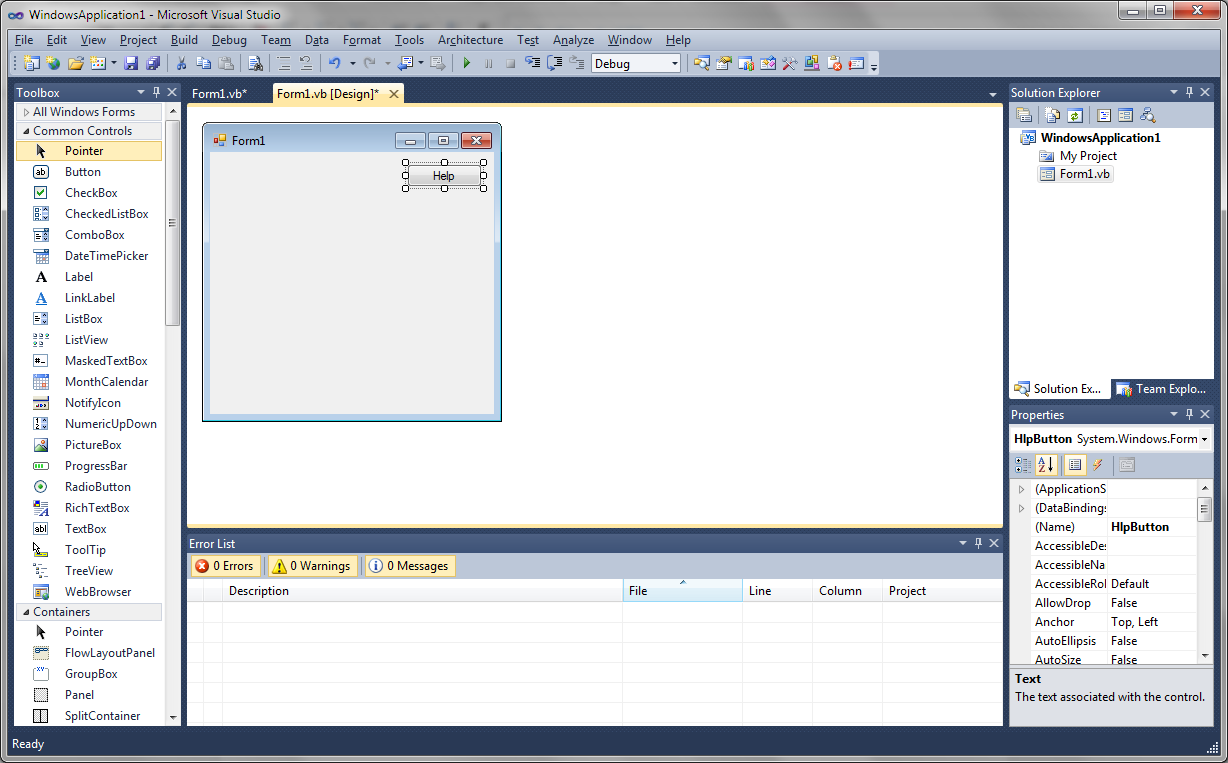
How to Create Help Files for Visual Basic (VBA.NET) Windows-Application in Dr.Explain
How to Create Help Files for MS Excel (VBA) Windows-Application in Dr.Explain
How to Create Help File for MS Access (VBA) Windows-Application in Dr.Explain
How to Create Help File for Delphi Windows-Application in Dr.Explain
2. Syncing with frequent releases and technical debt
When a product is updated weekly, the help system must keep pace. The solution is docs‑as‑code AI integration with CI/CD pipelines: every pull request to the codebase triggers documentation validation—a linter (e.g., Vale with custom rules) checks terminology, and automated tests verify that code examples match the current API. In addition, validity tags (valid_until) are added to each topic; after expiration, the topic is flagged as deprecated and excluded from the RAG pipeline.
3. Total cost of ownership (TCO) and pilot strategy
Migrating to a contextual infrastructure requires investment: re‑annotating 1,000 pages can cost anywhere from $20K to $100K depending on complexity, plus infrastructure costs for vectorization and team training. However, for companies with high support volume (over 10,000 tickets per month), ROI is typically achieved within 6–9 months through reduced operator time. A hybrid approach is recommended:
- Select 5–10 most frequent queries (from support data) and craft perfect responses for them.
- Structure the corresponding documentation sections, add metadata, and index them.
- Deploy a test chatbot and measure quality improvements (precision and recall metrics) over 1 month.
- Only after confirming ROI, scale to the remaining content.
4. Legal and ethical risks
When generating answers automatically from a knowledge base, the organization bears responsibility for accuracy. For critical scenarios, it is advisable to rely on human‑written content and maintain a full audit log of all responses. In 2025, the EU published the AI Act, which includes transparency requirements for sources—documentation must include traceable links back to the original source.
Bidirectional help systems and standardization
Over the next 2–3 years, we expect three key trends:
- AI‑to‑documentation feedback — AI agents will not only read but also suggest updates based on user inquiries. For instance, if a chatbot cannot answer a question, it automatically files a request for the technical writing team with details of the missing information. Companies like ServiceNow are already piloting such loops.
- Standardization of "AI‑ready docs" — analogous to
llms.txtfor websites, we expect new specifications to emerge (e.g., the W3C AI Knowledge Community is working on a standard for annotating instructions). By 2028, certifications similar to DITA for component‑based user guides are likely to appear. - Integration with enterprise knowledge graphs — documentation will be linked with other data (code, tickets, logs) in a unified graph, enabling AI to answer questions like "Why did error X occur with version Y?" by drawing on all available sources.
Practical checklist for technical writers and AI engineers
- Audit: inventory all content. Assess duplication (using tools like Duplicati or cosine‑similarity scripts). Use special tools for technical writers to automate duplication detection and terminology checks.
- Audit existing software user manuals for duplication.
- Terminology: create a unified glossary (in YAML/JSON format) and enforce usage rules (e.g.,
term: "preferred name"— always use exactly this). Integrate a linter to enforce compliance. - Markup: enrich each topic with metadata:
type: [concept, procedure, reference, troubleshooting],product_version,prerequisites,related_topics(URI). Use JSON‑LD or frontmatter. - Review your existing user guide templates and update them with AI‑ready metadata.
- Pilot set: choose 20–30 topics that cover 80% of support inquiries. Prepare them according to the new standards.
- Technical implementation: set up an indexing pipeline (e.g., using LangChain + Elasticsearch with vectors or Qdrant).
- Evaluation: build a benchmark of 100–200 questions with golden answers. Measure the percentage of questions where the correct chunk appears in the top‑5 (Hit Rate@5) and MRR. Target values for technical documentation: Hit Rate@5 > 0.85, MRR > 0.75.
- Monitoring: implement RAG logging with mandatory fields
retrieved_chunksandanswer_helpful(user rating). Build dashboards (Grafana, Kibana) to track trends. - Team training: conduct workshops for technical writers on semantic markup principles, RAG metrics, and vectorization fundamentals — these are essential AI tools for technical writers to master.
If you are just starting out—do not try to tackle everything at once. Begin with an audit: take 10 typical support questions and see how many can be fully answered by your existing help system (without human intervention). This will give you a solid baseline for prioritization.
Conclusion
In the age of generative AI, user documentation is a strategic asset that demands a systematic approach to architecture, metadata, and processes. Companies that ignore the shift toward contextual infrastructure will face a growing gap between user expectations of AI agents and the actual quality of service. However, a full transformation does not have to be costly or risky: a pilot approach, measurable metrics, and iterative improvement can deliver quick wins. Start with the 20% of content that delivers 80% of business value, and within a quarter you will see reduced support load, increased customer trust, and a clear roadmap for the future. In 2026, investing in modern documentation tools and knowledge base design is not just a trend — it is a competitive advantage that pays for itself within a year.